Right zip code, wrong address: why you can't just add knowledge to an LLM
I spent the last couple of weeks reading into how people combine knowledge graphs with LLMs. Knowledge graphs store facts as triples like (France, capital, Paris), structured and updatable. LLMs know a lot but hallucinate and go stale. Plenty of work tries to bridge the two: you can convert triples to text and put them in the prompt (KAPING), fine-tune with projected KG embeddings (ConceptFormer, TEA-GLM), inject KG entries as extra attention key-value pairs (KBLAM), or just edit the model’s weights (ROME, MEMIT).
I kept coming back to a simpler question: what if you just take a KG vector for “France,” project it into the LLM’s activation space, and add it to the hidden state? No fine-tuning, no weight editing, just vector addition on a frozen model.
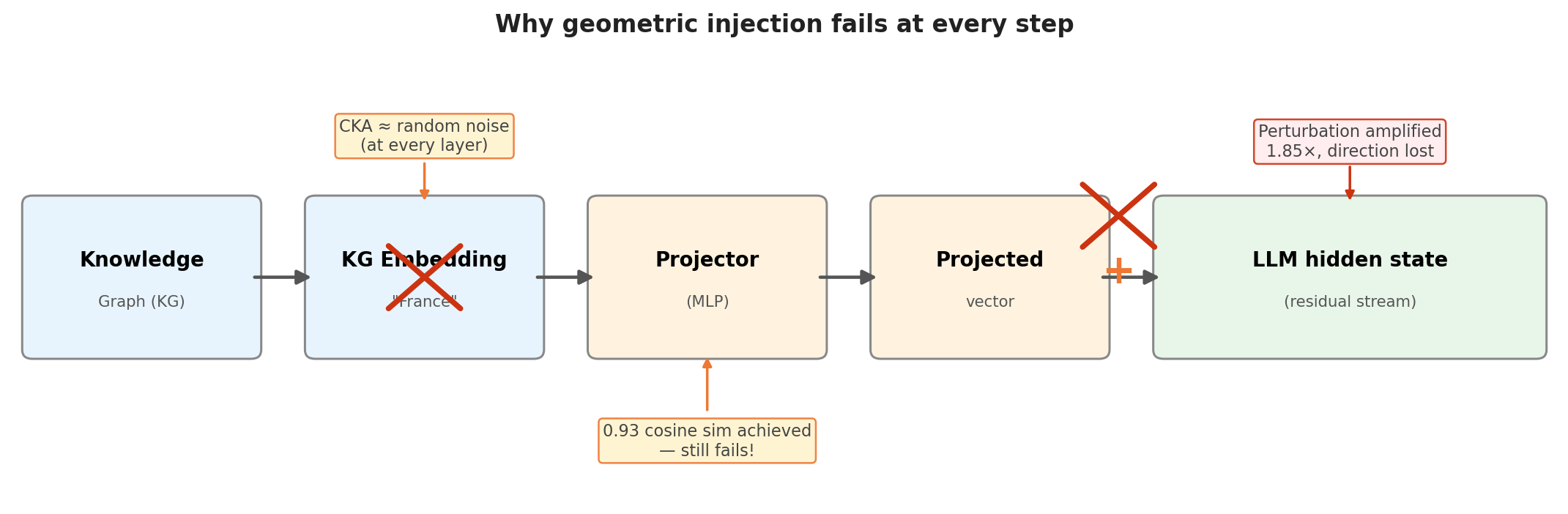
It doesn’t work. We tried 300 configurations on Pythia-1.4B with factual fill-in-the-blank questions from LAMA T-REx (baseline: 20% Hit@1). Five injection methods, five layers, four strengths, three positions. Every one degraded performance. Best result: ~14%. The KG vectors performed no better than random noise of the same magnitude.
KG embeddings are noise to the LLM, but the LLM knows the facts anyway
We measured representational similarity (CKA) between KG embeddings and Pythia’s hidden states. TransE, RotatE, and sentence embeddings all look identical to random noise at every layer. Three fundamentally different external representations, same result.
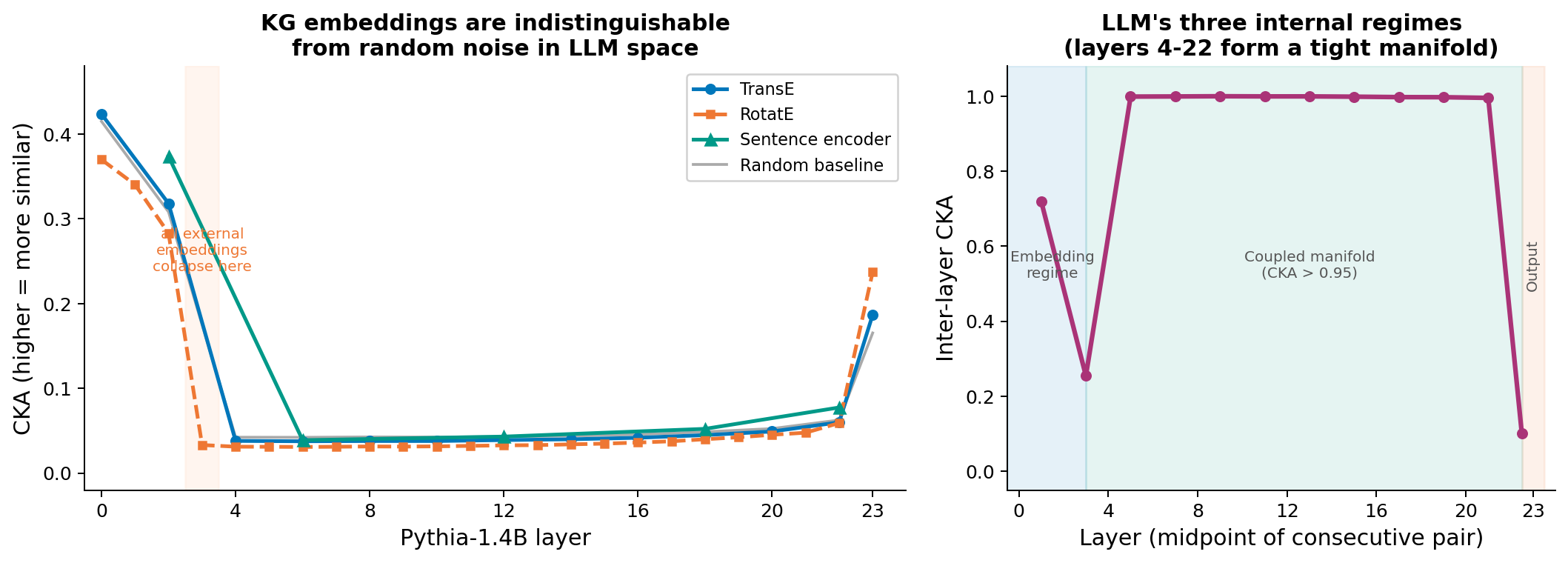 Left: all external embeddings overlap with the random baseline; the lines are inseparable. Right: Pythia’s inter-layer CKA exceeds 0.95 through layers 4–22, confirming the metric can detect real similarity. KG embeddings aren’t slightly misaligned. They’re orthogonal.
Left: all external embeddings overlap with the random baseline; the lines are inseparable. Right: Pythia’s inter-layer CKA exceeds 0.95 through layers 4–22, confirming the metric can detect real similarity. KG embeddings aren’t slightly misaligned. They’re orthogonal.
The interesting part: the LLM does encode relational structure internally. A linear probe on Pythia’s hidden states classifies relation type (capital of? native language of?) at 65% on a 15-way task (chance: 6.7%). The facts are there. The geometry is completely different.
Alignment is easy to learn, and useless
We trained an MLP projector: KG vector → Pythia activation space. With 10 examples we hit 0.93 cosine similarity to Pythia’s own representations. The alignment problem is trivially solvable. Injecting these aligned vectors still doesn’t improve accuracy.
We tracked why. An injected perturbation, whether carefully aligned or random noise, gets amplified (~1.85×) and rotated until its direction is essentially random by the final layer.
![]() Perturbation magnitude grows (left) and direction randomizes (right) through the network. The aligned vector (blue) and random noise (orange) reach nearly the same endpoint by layer 23. The transformer treats them identically; alignment washes out.
Perturbation magnitude grows (left) and direction randomizes (right) through the network. The aligned vector (blue) and random noise (orange) reach nearly the same endpoint by layer 23. The transformer treats them identically; alignment washes out.
Alignment buys tolerance, not benefit. The model can handle an aligned perturbation at higher strength before collapsing, but accuracy never rises above the clean baseline. Both aligned and random perturbations end up in the same place by the output layer.
A static KG vector, the same “France” whether you’re asking about its capital or its language, can’t target the specific internal features the model reads for each prediction. Right zip code, wrong address.
Part 2: a learned encoder gets 96% on a frozen LLM, and we trace where in the model the signal goes.
Comments