Five heads in layer 12: what a learned KB encoder actually learns
Part 1 showed that adding KG vectors to an LLM’s hidden state fails regardless of alignment. What works: train a small encoder to project KB entries into the model’s attention key-value space as extra tokens, as in KBLAM (Feng et al., ICLR 2025). The LLM stays frozen; the encoder learns which directions actually change the output.
We reproduced this on Pythia-1.4B and then asked where the signal goes.
The encoder works, and the shuffled-KB test proves it
Pythia gets 14% on factual probes by itself. With the encoder providing correct KB: 96%.
The convincing number is the shuffled-KB result: 5%, below the 14% clean baseline. When given the wrong entity’s fact in the right format, the model follows it. The injection is live, not decorative.
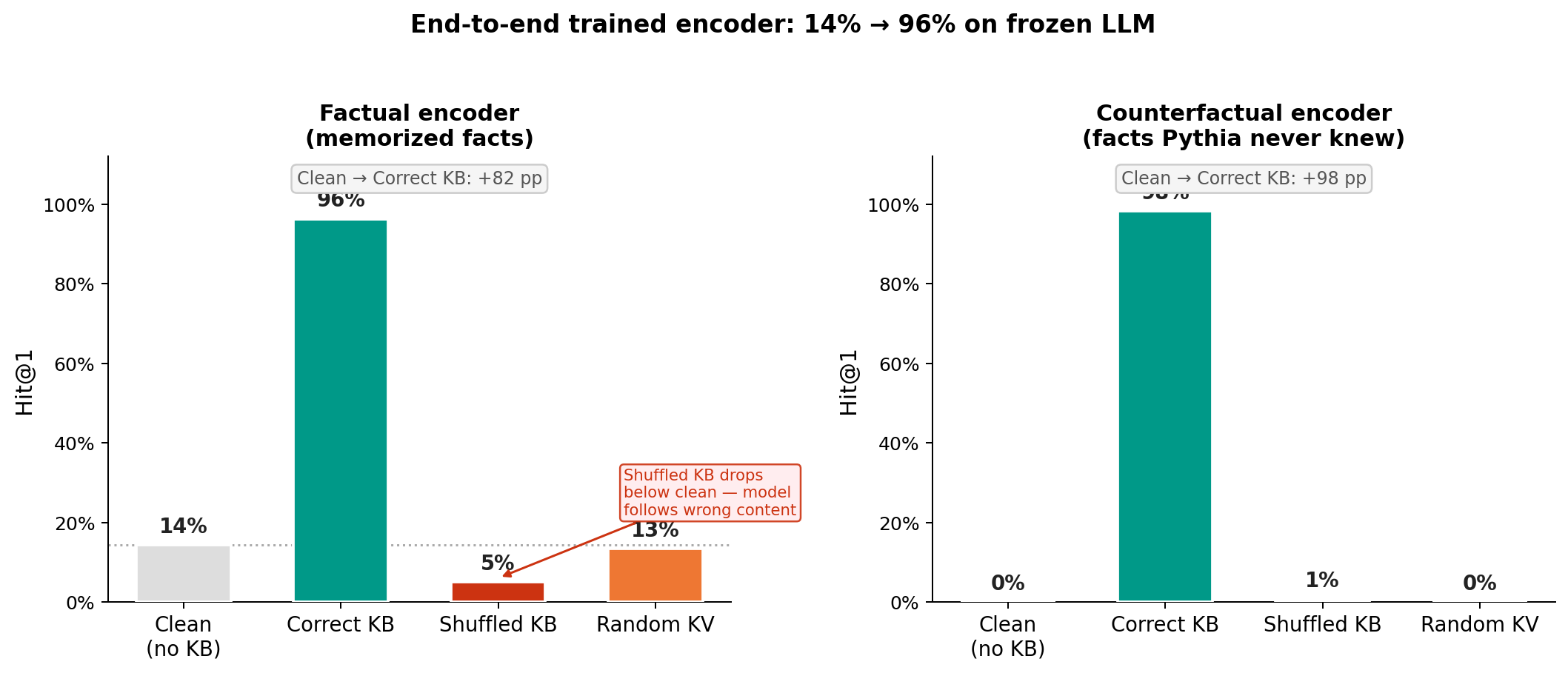 Left: factual encoder, 14% baseline jumps to 96% with correct KB, drops to 5% with shuffled KB (below clean). Right: counterfactual encoder on facts Pythia has never seen, 0% baseline rises to 98%. Both show the model actively reads and follows the injected signal.
Left: factual encoder, 14% baseline jumps to 96% with correct KB, drops to 5% with shuffled KB (below clean). Right: counterfactual encoder on facts Pythia has never seen, 0% baseline rises to 98%. Both show the model actively reads and follows the injected signal.
The counterfactual result is the stronger test: these are facts Pythia’s parametric memory assigns near-zero probability. The encoder writes new facts into a frozen model.
The signal concentrates in layer 12; head identity doesn’t matter
The encoder injects into 64 head-layer slots (4 layers × 16 heads). We added a learnable on/off gate per head with a sparsity penalty (Hard Concrete L0; Louizos et al., 2018) and trained two encoders with different penalty strengths.
Both converged to the same answer: zero out layers 0, 6, 18. Keep only layer 12.
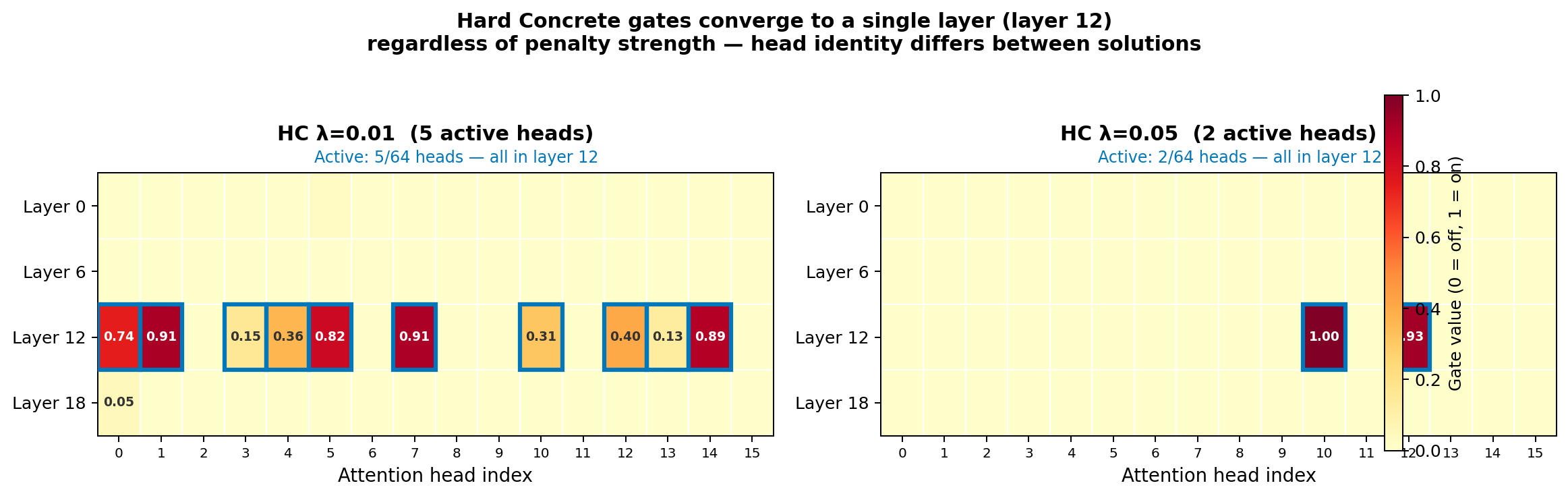 Two independently trained sparse encoders both concentrate all signal in layer 12. The active heads are completely disjoint, {0,1,5,7,14} vs {10,12}, yet achieve comparable accuracy. Layer identity is consistent across solutions; head identity is arbitrary.
Two independently trained sparse encoders both concentrate all signal in layer 12. The active heads are completely disjoint, {0,1,5,7,14} vs {10,12}, yet achieve comparable accuracy. Layer identity is consistent across solutions; head identity is arbitrary.
Layer 12 is where Pythia’s relation-probing accuracy peaks and roughly where causal tracing methods (ROME, Knowledge Neurons) localize factual recall. The encoder discovered this on its own.
Sparse vs all-heads: no difference
You might expect fewer heads to mean less interference. Each head independently attends to all KB triples including distractors, so inactive heads import noise into the residual stream. The math predicts an optimal head count well below 64 (cross-head interference scales as H^2 while signal scales as H, via a Hanson-Wright-style argument).
We tested this by training an all-heads encoder from scratch (penalty disabled, all 64 heads free) and sweeping KB size. No difference. All three configurations (64, 5, 2 heads) overlap within bootstrap CIs at every KB size. Restrict the encoder to 5 heads and it routes the signal more strongly through those 5. Give it 64 and it spreads out. The bottleneck is the encoder’s mapping quality, not head count.
Practical takeaway: train end-to-end, inject into the right layer, and don’t bother optimizing over head selection.
Comments